

来源:没错我叫刘怼怼
2025年的第一只黑天鹅,比以往时候来得都早一些。
农历春节假期,正在全国乃至全球大迁徙的中国人民,突然被一个叫作DeepSeek的AI大模型硬控了。
这几年国内大模型层出不穷,2024年中Kimi屠过榜,年底豆包火了一把,很多人认为字节要在大模型中超车了,结果舆论没炒几天,DeepSeek突然爆发成国民级应用。
——超过此前所有大模型在国内翻搅起的热度。
当然ChatGPT不算啊,我说国内的大模型。
我相信此时此刻,应该没几个人还没用过DeepSeek吧。
上一条稿发出去之后,本来我还储备了几个选题要写的,结果每天玩DeepSeek玩到深夜,很上瘾。
倒也不是没玩过大模型,大家还有印象的话,2022年我就记录过跟ChatGPT浅浅的聊天。(→ChatGPT说,中国的房子还能买哈哈)
也是持续在关注这方面的动态,跟Kimi、豆包不一样,DeepSeek突然出圈时,它的R1模型的深度思考能力,带给我的是革命性应用的震撼,我当时就跟朋友说:
今年,一定会发生颠覆性的变化。
不管是对整个社会,还是对于我们所在的行业,广州的楼市。
很多逻辑要改写了。
但是,很多人用了DeepSeek之后,觉得它也不过如此,顶多就是个搜索引擎而已;
依据就是,我想要用它写点东西,做个攻略,弄个工作报告,写个论文啥的,其实都没有外界所宣称的那么好,出来的东西要么太过浮夸,要么信息不准确,不切实际。
所以今天这条稿,我想来说说:
为什么我觉得DeepSeek是一款堪称革命级的应用,它到底牛在哪儿?
怎么去判断DeepSeek输出内容的准确性?
DeepSeek到底会对广州的买房市场带来什么具体的变化?
以及,我们怎么去科学使用它?
1
如果还没有好好用过DeepSeek,那么我接下来说的一切都会像隔靴搔痒,很难感同身受。
所以,先要解决的第一个问题是:
DeepSeek官网这么堵,有哪些好的方法,可以流畅使用它?
(对了解DeepSeek以及如何设置它不感兴趣的,可直接拉到第3趴)
从大的类别来说,一个是本地化部署,一个是第三方服务器云端部署。
首先,我不推荐本地化部署。
原因就一个字:贵。
目前,DeepSeek有两个模型,R1和V3.
V3是轻量化模型,算力要求低,适用于小规模训练;
R1是大规模预训练模型,算力要求很高,用于大规模数据处理和高性能运算。
目前网上爆火的是R1,火出圈的就是它的深度思考能力,其复杂的推理目前国内其他模型都难以望其项背。
所以,我们日常说的DeepSeek,实际上指的就是DeepSeek的R1模型。
好了,在这个背景之下,我们来看本地化部署R1模型需要的硬件配置,到底得花多少钱。
先说结论:几千块到100万+不等。
是的,如果想把R1的算力拉满,需要花费上百万元人民币。

为啥差别这么大?
事实上,R1模型提供了从1.5B到671B的不同选择,参数规模越大,所需的算力就越高,当然就越费钱。
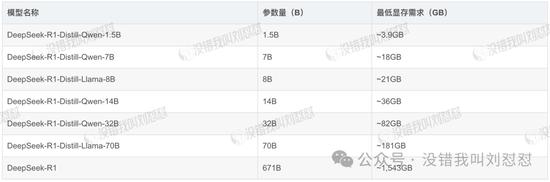
你看,671B的“满血版”,需要的算力高达1543G!100多万不是白花的……
参数量越大,能进行的推理就越复杂,得出来的答案可能就越令人满意。
你说,不对,我用笔电或者家里的台机也成功搞了个本地化,一点都不卡了噢。
是的,普通消费级的家用配置,也是能配个1.5B到7、8B的,这个量级确实不卡。
671B以下的叫“蒸馏版”,这也就是为什么同样的问题,不同的人去问DeepSeek得到的答案会不同——
如果你总是用1.5B的模型去跟它聊天,一定会觉得DeepSeek也没那么好用嘛;
但你要用的是671B的“满血版”,体感就很不一样。
然后这两类人会给出截然不同的评价:一个会说DeepSeek不过如此,盛名之下,其实难副,一个就觉得果然是神级应用啊。
所以,有没一种可能是,低算力的R1模型,影响了你的对DeepSeek的判断?
所以,我也非常建议大家通过第三方的云端部署,低成本去使用满血版的R1,体验感拉满。
2
那么,具体怎么做云端部署呢?
亚马逊之类的国际云就不说了,毕竟服务器在国外,国内用起来其实没那么方便。
国内目前很多云服务都接入了DeepSeek,但要支持满血版的R1,主要是和华为云合作的硅基流动,以及字节旗下的火山引擎。
先说硅基流动。
跟火山的设置相比,硅基流动的部署可以说是相当简单了。
这也导致大多数人在遭遇了官网的日常卡顿后,纷纷转投硅基流动,目前硅基也会时不时掉一下,但跟官网动辄“服务器繁忙”相比,硅基速度虽慢,至少能用。

部署硅基流动就两步:
第一步,注册账号并创建API。
第二步,下载客户端,粘贴在硅基流动获取的API密钥即可。
然后就能刷刷刷打字,疯狂调戏DeepSeek了。
硅基流动的注册地址是:
https://cloud.siliconflow.cn/i/iv0veX6G
用手机号收个验证码就算注册了,很简单。
大家也可以在注册时输入我的邀请码:iv0veX6G
这样我俩都能得2000万Tokens,后台实际到账是14元的平台配额,以我的经验来说,即便每天都跟DeepSeek高频互动,也足够用一个月了。
这是官方送的羊毛,不薅白不薅。
注册成功之后,在左边菜单栏选“API密钥”,新建一个自己的密钥。
然后复制密钥。

硅基流动的动作就完成了。
接下来是下载客户端,我用的是Chatbox AI。
首次登陆会有个提示页面,选“使用自己的API Key”就行,之后也可以在“设置”里重新修改。
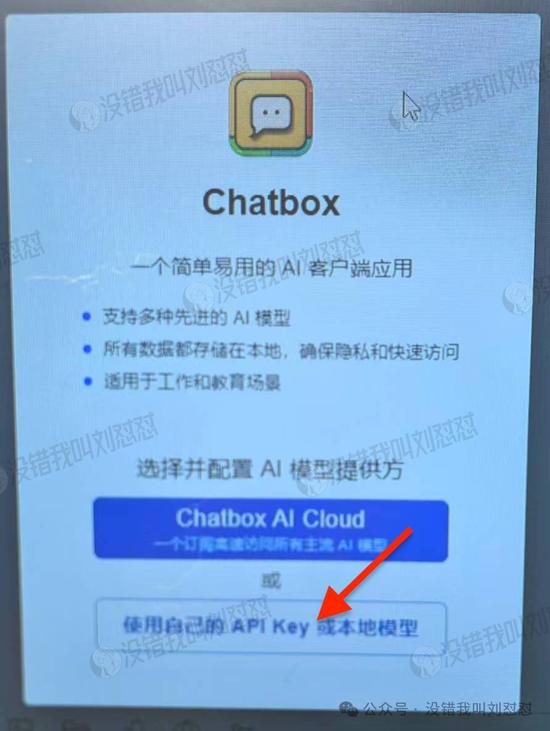
“模型提供方”选“SilliconFlow API”:
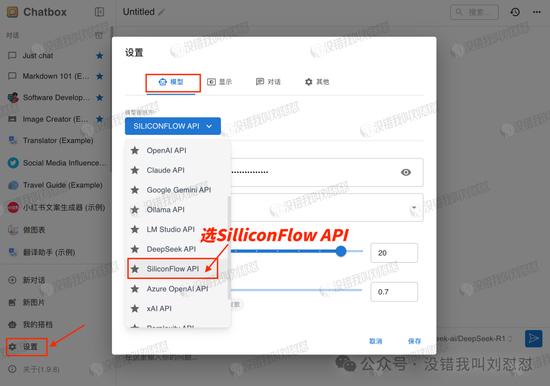
粘贴“API密钥”:

“模型”选DeepSeek-R1。
全部保存就能随便用了。
硅基流动+Chatbox AI的方案,真的是简单又好用。
当然,如果不想弄客户端,还有个更简单的办法——
直接在硅基流动的网站上在线体验满血版R1:
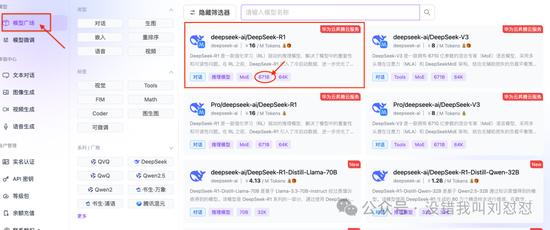
“模型广场”出来的第一个,就是满血版,判断标准就看是不是671B。
点“在线体验”,直接用。
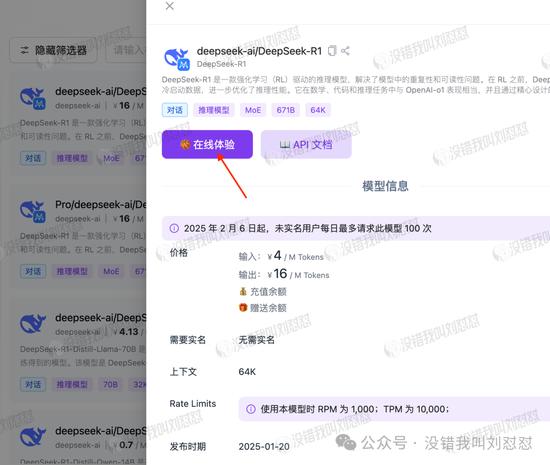
硅基流动的部署和在线使用就这些了。
相对于硅基流动,火山的部署门槛就要高很多了,用的人也少很多,加上字节的算力比其他家都强,所以火山用起来确实“嗖嗖”的。
(温馨提示:火山的设置有点复杂,如果觉得硅基流动就够用的朋友,可以直接拉到第3趴。)
以下是火山的设置方法——
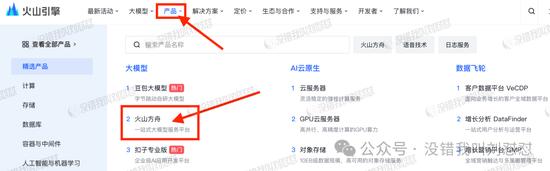
首先,在火山引擎的产品栏里,选“火山方舟”:
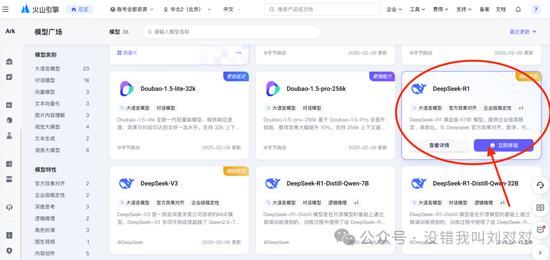
注册成功之后,每个模型官方都会送50万Tokens的额度,同样能在模型广场直接选满血版在线体验:
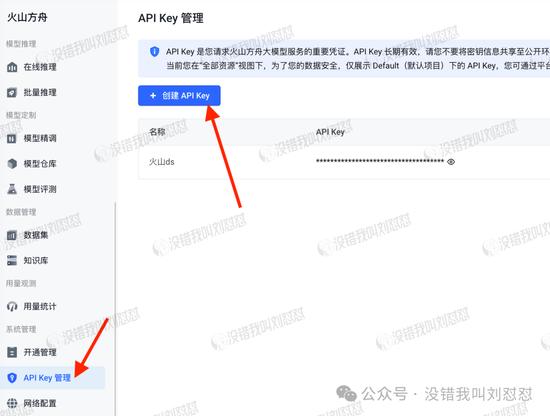
自行部署的话,也是先新建API密钥,跟硅基流动一样:
然后“在线推理”,创建推理接入点:
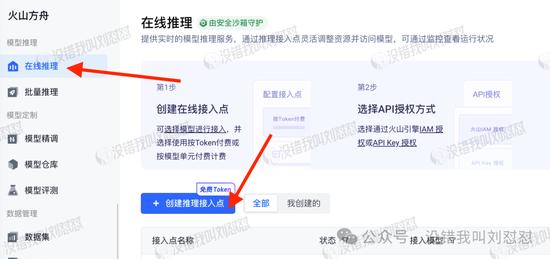
名称随便填,模型选R1:
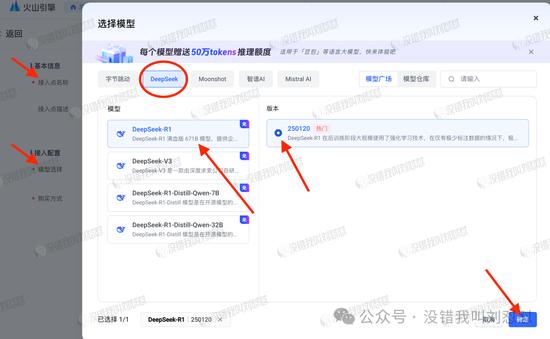
接入后,点名称进去看详情页:
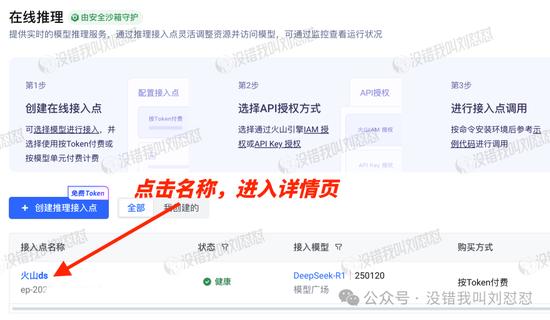
选API调用、通过API Key 授权、第三方SDK调用示例:
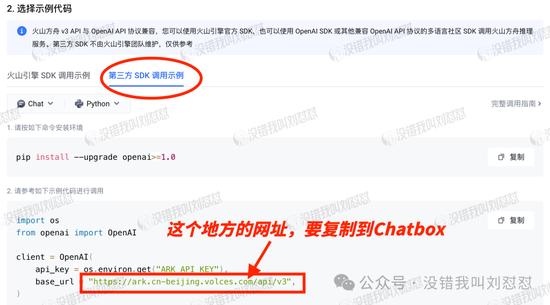
设置Chatbox客户端,模型提供方选自定义:
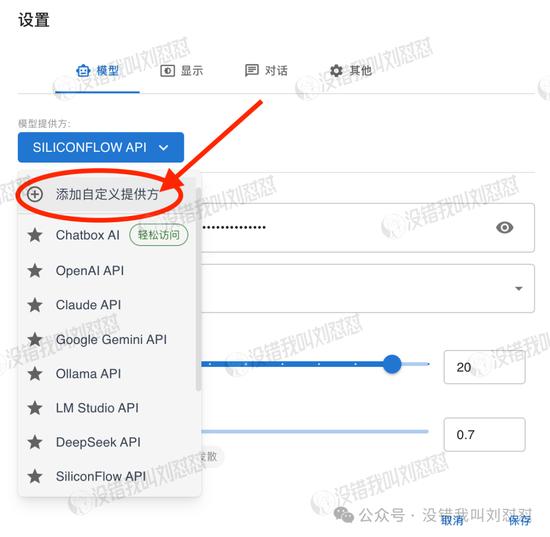
如图所示进行设置:
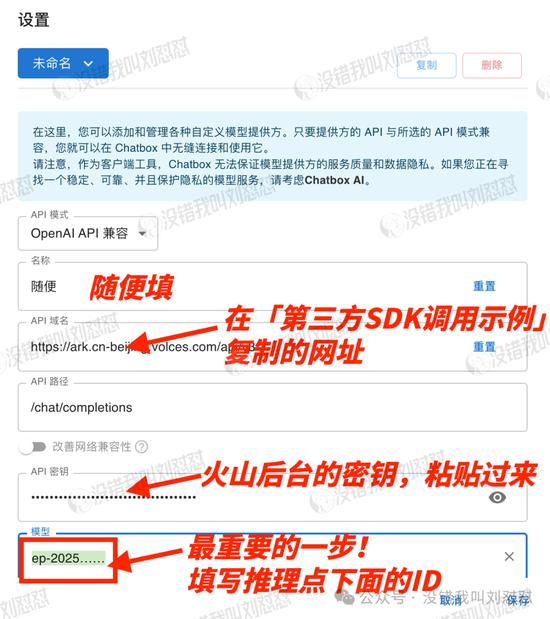
选模型的时候特别要注意!
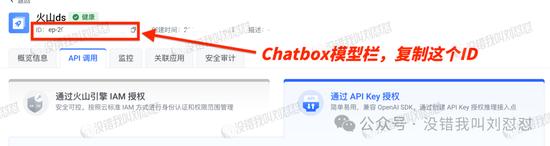
输入的是在火山“推理接入点”的ID,ep-2025开头的那一串数字。
然后保存,就设置好了。
以上是硅基流动和火山引擎的云端部署步骤,确实长,大家设置过程中有啥疑问,可以加我微信,探讨探讨。
3
现在来说说我的使用体验。
为啥我觉得,今年,DeepSeek就能在全社会掀起颠覆性的变化?甚至重塑整个社会的游戏规则?
首先,肉眼可见的,DeepSeek是目前为止,国内大模型中,“普世度”最高的一款。
春节期间,哪怕是我老家那种三线小城,大家都在讨论DeepSeek这个东西了。
当然,这跟此前大多数模型都不开源有关。
我一直觉得,一个新事物只有发展到全民皆知,人人言必称之,成为一种再不跟风就晚了的“社交资本”,才有可能迎来行业的拐点。
现在越来越多的企业宣布接入DeepSeek——
比如汽车领域,吉利、东风、长安、长城说,要把DS应用到智能座舱交互和车控系统,极氪、智己、Smart则要聚焦语音交互,提升对用户意图的预测。
能源领域,国家电网、中国中化已经接入DeepSeek;
通信领域,国内三大通信运营商,移动、电信、联通也部署了R1模型;
金融领域,国金证券、兴业证券等券商接入DeepSeek,用来优化客户服务和智能投研;
还有医疗、教育、传媒等。
截至2月5日,国内已经有超过160家企业接入DeepSeek。
当然最重磅的是——微信。
是的,就连微信,都接入DeepSeek了……
这里面多少有国家下场助攻的影子,但也有市场自身力量的推动,不管怎么说,AI大模型在今年的爆发,基本是毫无悬念的事——
因为它已经从实验室研发的Demo阶段,全面扩散到了真实世界的应用层面,实现了全社会“应用场景”的无限扩张。
无论是从DeepSeek的开源模式来说,还是当下“日日新,又日新,苟日新”的全民普及和渗透度,都是时候了。
何况,此时此刻,还只是2025年的开头。
今年接下来的日子会怎么迭代,真的很值得期待。
4
那么,回到房地产来说,DeepSeek会对行业产生什么影响?
房企内部一定会更卷。
‘人效’这个词,一定会在企业内部被无限放大。
应对之策,至少要比你的领导先懂DeepSeek,更懂DeepSeek,用魔法打败魔法。
而对于房产交易来说——
那些专业度不够,很难生产自己的原生观点,一直靠着全网“学(xi)习(gao)”再对外输出的从业者,职业危机可能要来了。
以后购房者只需要两种价值:
一种是楼盘的基本资讯。
包括项目和销售提供的楼书,这是最基本的;
还有楼盘隐藏的不利因素,比如地块的环评有没问题,预售之后是否会有不利的公建因素如立交桥、大型垃圾站等尚未公布等。
能提供越多关于楼盘隐藏资讯的,越有价值。
一种是买房的深度选筹能力。
现在但凡是个房产交易的从业者,一上来就要跟你讲学铁商,把已有信息翻来覆去换着话术来回说——
要么就是放大学位价值,你看这个配建的学校是名校集团的成员校噢,老牛了;
要么就是放大配套价值,你看这几个商业,厉害的嘞,太古汇知道不?全中国有几个?广州有几个?其中一个就在这儿!山姆、Costco都争着要来的地方,怎么都错不了!华润万象系啊,太古+华润的双商业,未来潜力无限!
要么,就说地铁规划,哪个线在建,通了你得多方便之类的。
无非就是把学铁商的信息进行排列组合,放大一些因素,套用在购房者的学位、通勤、预算和居住要求的排序里。
基本就是一个筐,就着购房的需求就哐哐往里装,怎么说都对,反正也挑不出毛病。
但是!
从今往后,这些简单的选筹建议,是不是可以问问DeepSeek了?
它是个莫得感情的AI机器啊,至少客观嘛不是?
比如,我来上个实操的案例,问问DeepSeek,要不要为了学位放弃海珠的大房子,搬去越秀?
你们看看它咋说的——


先看深度思考的推理结果:
第一,海珠也有学位预警,如果你在海珠的房子属于预警的学区,要注意入学的确定性。
第二,你问这个问题,可能担心的不仅仅是学位数量,还担心海珠的整体教育质量。
第三,越秀作为广州的教育强区,学位房比较稳定,招生地段变化小,入学确定性高,即使招生地段变化,学校资源的差异也不大,保险系数也高。
第四,但越秀的学位房多为老破小,价格高,居住环境不如海珠的大房子,未来也更难卖。
第五,越秀地产在海珠拿了些新地块,今年入市,可能给海珠带来新的学校资源。
总结下来的选筹建议就是:
综合权衡教育质量、居住条件、经济负担以及未来的房产价值,如果教育是首要考虑,越秀的学位房更优,但要接受较高的房价和较差的居住环境。
如果看中居住舒适度和经济性,海珠可能更合适,但需面对可能的学位紧张和被统筹的风险。
以上就是DeepSeek的全部推理。
你看,作为购房者,你问的很多从业者,他们都未必能超出这个选筹分析。
DeepSeek随便从50个网页里思考37秒,就能得出这个结论,而且你还可以不断问它,它还能不断给你修正和完善,关键是:客观啊。
如果真实世界的人给你的选筹建议,并没有超出这个水准,而且还会在选筹中时不时“夹带私货”,那么,很快,大家问问DeepSeek就完事了。
不久的将来,当DeepSeek像微信一样高频出现在我们的生活中,并且得以高频使用,购房者需要的,一定是超出DeepSeek整合水平的更专业的深度选筹能力。
要想不被淘汰,还是赶紧跟洗稿洗观点说拜拜吧。
小心时代抛下你的时候,连招呼都不打。
5
当然,DeepSeek也不是全能,现在它被诟病的最厉害的就是幻觉严重,给出的信息常常不真实,不准确,甚至差个十万八千里。
原因在于R1模型的研发定位,是一个强在逻辑推理的模型,如果想要更准确的信息,得你自己投喂。
或者挂载一个外部知识库。
你用它去检索信息,并根据检索结果做大量的数据处理,得出来的结果大概率有很大偏差。
工欲善其事,必先利其器。
用对地方了,它才无敌。
