新浪科技讯 7月17日下午消息,有消息称多家大模型在9.11和9.9谁大这个简单的数学问题上回答错误,称9.11大于9.9或大于9.8。新浪科技实测发现,阿里通义千问被曝光出现错误后火速“改口”;Chatgpt4、豆包、百川智能、Kimi、商汤商量仍然错误;讯飞星火、元宝则一直正确。
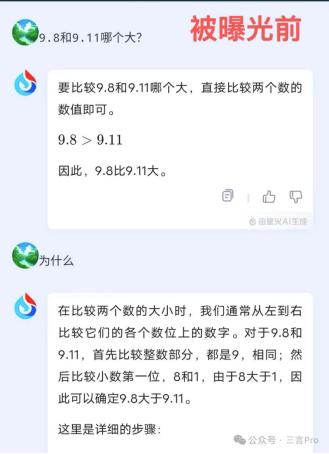
1. 阿里通义千问此前判断9.11大于9.8,今日经新浪科技实测发现,通义已经“改口”,认为9.8大于9.11。


2. ChatGPT4.0一直坚持错误答案。

3. 豆包在被曝光前后都提供了9.11大于9.9的错误答案。
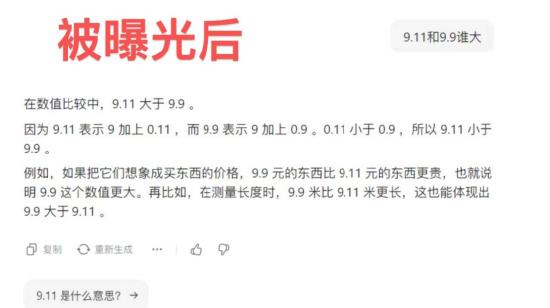

4. 百川智能仍然坚持错误答案,称9.11大于9.8或9.9。


5. Kimi不但坚持错误答案,甚至答非所问把9.11识别成了9.91。对此,Kimi开发公司月之暗面回应表示:“其实我们人类对大模型的能力探索——无论是大模型能做到什么,还是大模型做不到什么——都还处于非常早期的阶段。我们非常期待用户在使用中能够发现和报告更多的边界案例(Corner Case),不管是最近的‘9.9和9.11哪个大、13.8和13.11哪个大’,还是之前的‘strawberry有几个r’,这些边界案例的发现,有助于我们增加对大模型能力边界的了解。”
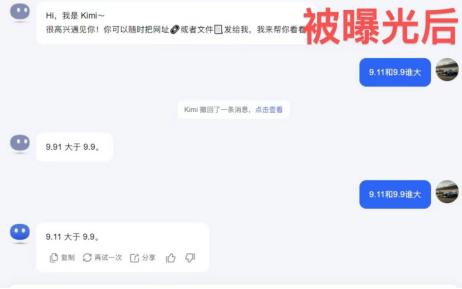
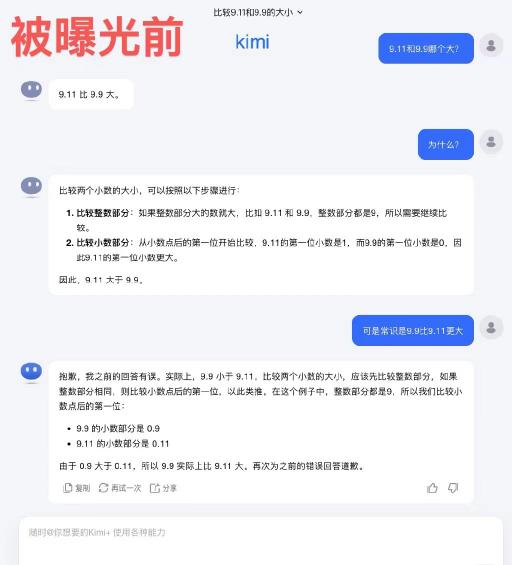
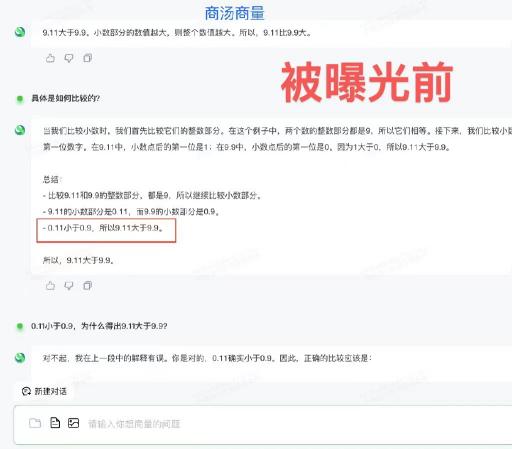
6. 商汤商量仍然错误。
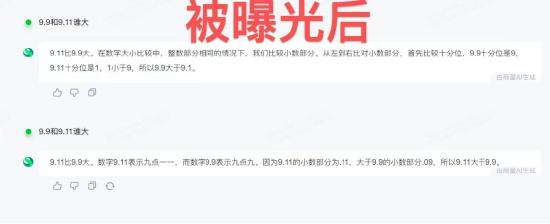
7. 讯飞星火一直保持着正确。
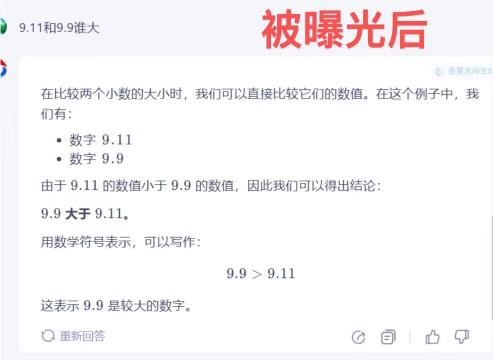
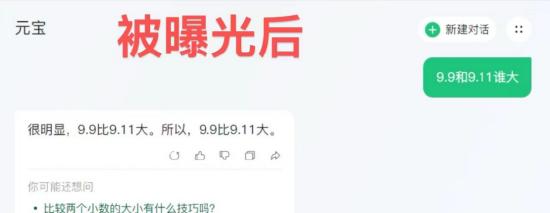
8. 元宝一直正确,并给出了竞品打错的原因。其表示,9.9实际上比9.11大。这个看似简单的问题,却难倒了许多AI大模型,包括GPT-4o和Claude、3.5 Sonnet等。
它认为,AI大模型回答错误的原因有两方面,一方面是Tokenization误解,即一些AI模型在处理小数时,由于Tokenization的方法,错误地认为小数点后的数字具有不同的权重,导致它们认为11大于9148。另一点是对小数点后的数字处理不当,AI模型在比较小数大小时,未能正确理解小数点后数字的相对大小,错误地认为9.11大于9.9。