

来源:DeepTech深科技
新加坡国立大学博士研究生张傲是第一作者,新加坡国立大学博士后研究员姚远担任通讯作者。

图丨张傲(来源:张傲)

能直接定位对象的准确位置,将多模态大模型的图像理解拓至区域级推理
如上可以看出,目前的多模态大模型通常建立在大语言模型的基础之上,通过配备视觉感知模块来获取多模态感知能力。
例如,由谷歌DeepMind 团队推出的视觉语言模型 Flamingo,借助具有重采样器的预训练视觉骨干提取视觉信息,并通过交叉注意机制将它们合并到文本特征中。
BLIP-2 和 Kosmos 模型则是直接将视觉特征作为软提示词,输入进大语言模型。
不过,这些已存在的多模态大模型只能将整个图像作为输入和输出的文本,也就是仅仅局限于从整体上理解图像,无法处理区域级推理任务,比如基于多模态对话,定位图片中的某个对象。
因此,为了进一步提高视觉理解水平,实现用于区域级推理的多模态大模型,当前的解决方案一般选择利用 Pix2seq 方法[2],也就是把对象的边界框坐标,转换为大语言模型能够理解的一系列纯文本标记。
而后者只需根据这种纯文本标记,就可以生成对象坐标,用户也就能够知道对象在图像中的位置。
但是,该方法也存在一定的缺陷,即只擅长生成对象的边界框,这难以直接地拓展到最能表示对象准确位置的图像掩膜。
其中,需要说明的是,在图像处理和计算机视觉领域,掩膜指的是在不影响图像其他部分的情况下,对图像局部区域进行某些精细的操作。
“我们希望多模态大模型能够非常方便地拓展到复杂的位置形式,就提出把对象的位置信息转化成特征形式,然后全部用该特征进行编码解码,以完成所有对象定位格式的统一。”张傲解释道。
据此,他们构建了 pix2emb 方法。该方法的关键思想在于,先把全部有关位置的信息建模为嵌入,然后通过相应的解码器将其解码为目标格式。
具体来说,研究人员分别引入了“
在文本生成过程中,前者会触发定位解码,它的隐藏状态就可以用于检测和分割,而预测或提供的对象位置,则被编码到后者标记的嵌入中,以供对象引用。
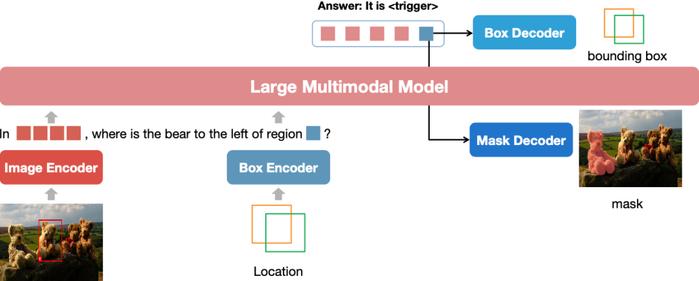
图丨NExT-Chat 的整体框架。图像和给定的边界框分别由图像编码器和框编码器进行编码。在解码过程中,

实现对象定位、区域描述、推理等能力,通过定性方式和定量方式进行验证
采用上述方法,该课题组通过一个包含预训练、指令调优和分割训练三个阶段的训练过程,完成了对 NExT-Chat 的训练。
在第一阶段,他们使用 Flickr30K Entities、Visual Genome 等各种来源的混合数据集,在保持冻结图像编码器的同时,对包含框解码器的整个大语言模型进行训练。
据了解,该阶段的训练耗时约 59 小时,用了 8 个 A100 GPU(80G)。
在第二阶段,又进一步采用来自 VQAv2、RefCOCO、Flickr30K Entities 等测试集的数据对模型进行微调,同样使用 8 个 A100 GPU(80G),训练时长为 10 小时。
经过前两个阶段的训练,该模型已经具备边界框解码能力,也就是能够进行对话和图像定位。
而在第三阶段,研究人员则通过 8 个 A100 GPU(80G)的 3 小时训练,将模型的能力拓展至分割。
据张傲介绍,NExT-Chat 训练完成以后,他和团队便通过定性和定量两种方式,对其有效性进行了验证和评估。
首先是定性验证。研究人员通过对不同场景进行实验,验证了 NExT-Chat 的功能。
例如,如下图所示,在定位复杂对象方面,该模型能够准确地检测并分割查询的对象,如背景中的熊。
在这里,值得一提的是,为了确保 NExT-Chat 不会偏向特定对象,该团队通过不同的查询对它进行测试,也就是让它分别查找背景中的四只熊。

图丨NExT-Chat 的视觉定位示例(来源:arXiv)
而后,该课题组又让该模型根据给定的边界框生成对象描述,以评估 NExT-Chat 在区域描述上的有效性。
如下图所示,当输入“给我一个图片中区域的描述”时,NExT-Chat 始终能够生成专门针对所提供区域的准确描述,即左图的“树是绿色的”,以及右图的“一个白色的灯开关”。
“可以看出,在右图这张有人存在的图片中,NExT-Chat 可以对背景里的小物体进行准确的描述,比如这个白色的灯开关。”张傲表示。

图丨NExT-Chat 的区域描述示例(来源:arXiv)
更有意思的是,该模型除了具备上述能力,还具有针对给定问题生成详细解释的能力。
如下图所示,当对该模型提问“图中男子的潜在工作是什么?请包括对象位置并解释”时,它能够通过分析上下文线索,比如男子穿的制服和骑的马,来推断他的职业可能是一名警察,或负责公共安全保护等职务的执法人员。

图丨NExT-Chat 的推理示例(来源:arXiv)
其次是定量验证。研究人员将 NExT-Chat和LLaVA、MiniGPT-4 等现有的 SOTA 多模态大模型,进行了综合评估。
结果显示,该模型在幻觉、分割、检测等视觉定位任务中,均取得比较优秀的效果。
此外,他们还验证了区域描述等其他任务,发现 NExT-Chat 也都能在不经过专门训练或微调的情况下,达到比此前基于少样本学习训练出的模型更好的效果。
据张傲介绍,该研究始于 2023 年 6 月,前后经历半年时间。一开始,该课题组仅仅打算做出有关掩膜的定位。
但当对模型的效果进行初步验证的时候,他们发现该领域已经有其他课题组用相似的方法实现了掩膜功能。
因此,为增强成果的创新性,他们在该功能的基础上进行了扩展,不仅让模型能够同时描述多个物体的位置,还额外增加了位置输入的能力。
另外,考虑到掩膜是一种非常昂贵的标注,所以他们也采用将少量昂贵的标注和大量廉价的标注相结合的方式,实现在不影响模型效果的前提下,对昂贵标注需求的缩减。
而在目前研究的基础上,该团队也计划进一步增强 NExT-Chat 检测和分割的效果、性能和速度,使它能够被更好地部署在手机或其他终端上。
参考资料:
1.A., Zhang, Y., Yao, W., Ji. et al. NExT-Chat: An LMM for Chat, Detection and Segmentation.arXiv:2311.04498(2023).https://doi.org/10.48550/arXiv.2311.04498
2.T., Chen, S., Saxena, L., Li. et al. Pix2seq: A language modeling framework for object detection.arXiv:2109.10852(2021).https://arxiv.org/abs/2109.10852
运营/排版:何晨龙
