


GPT-4 与机器人又擦出了新的火花。

在机器人领域,实现通用机器人策略需要大量数据,而在真实世界收集这些数据又耗时费力。尽管模拟为生成场景级和实例级的不同体量的数据提供了一种经济的解决方案,但由于需要大量的人力(尤其是对复杂任务),在模拟环境中增加任务多样性仍面临挑战。这就导致典型的人工模拟基准通常仅能包含数十到数百个任务。
如何解决呢?近年来,大语言模型在自然语言处理及各类任务的代码生成方面不断取得重大进展。同样,LLM 已经应用于机器人的多个方面,包括用户界面、任务和运动规划、机器人日志总结、成本和奖励设计,揭示了在物理基础和代码生成任务上的强大能力。
在近日的一项研究中,来自 MIT CSAIL、上海交通大学等机构的研究者进一步探究 LLM 是否可以用来创建多样化的模拟任务,并进一步挖掘它们的能力。
具体来讲,研究者提出了一种基于 LLM 的框架 GenSim,它为设计和验证任务资产安排、任务进展提供了一种自动化机制。更重要的是,生成的任务表现出了极大的多样性,促进了机器人策略的任务级泛化。此外从概念上讲,利用 GenSim,LLM 的推理和编码能力通过中间合成的模拟数据被提炼成了语言 - 视觉 - 行动策略。

论文地址:https://arxiv.org/pdf/2310.01361.pdf
GenSim 框架由以下三部分组成:
首先是通过自然语言指令提出新任务以及相应代码实现的提示机制;
其次是缓存以前生成的高质量指令代码以用于验证和语言模型微调的任务库,并作为综合任务数据集返回;
最后是利用生成的数据来增强任务级泛化能力的语言调整多任务策略训练流程。
同时该框架通过两种不同的模式运行。其中在目标导向设置中,用户有特定的任务或者希望设计一个任务课程。这时 GenSim 采取自上而下的方法,以预期任务作为输入,迭代地生成相关任务以实现预期目标。而在探索性环境中,如果缺少目标任务的先验知识,则 GenSim 逐渐探索现有任务以外的内容,并建立与任务无关的基础策略。
在下图 1 中,研究者初始化了包含 10 个人工策划任务的任务库,使用 GenSim 对它进行扩展并生成 100 多个任务。

研究者还提出了几个定制化的指标来渐进地衡量生成模拟任务的质量,并在目标导向和探索性设置中评估了几种 LLM。其中对于 GPT-4 生成的任务库,他们对 GPT-3.5 和 Code-Llama 等 LLM 进行有监督微调,进一步提升了 LLM 的任务生成性能。同时通过策略训练定量地衡量任务的可实现性,并提供不同属性的任务统计数据和不同模型之间的代码比较。
不仅如此,研究者还训练了多任务机器人策略,与仅仅在人工策划任务上训练的模型相比,这些策略在所有生成任务上都能很好地泛化,并提高了零样本泛化性能。其中与 GPT-4 生成任务的联合训练可以将泛化性能提升 50%,并在模拟中将大约 40% 的零样本任务迁移到新任务中。
最后,研究者还考虑了模拟到真实的迁移,表明在不同模拟任务上的预训练可以将真实世界的泛化能力提升 25%。
总之,在不同 LLM 生成的任务上训练的策略实现了对新任务的更好任务级泛化能力,彰显了通过 LLM 扩展模拟任务来训练基础策略的潜力。
Tenstorrent AI 产品管理总监 Shubham Saboo 给予了这项研究很高的评价,他表示,这是 GPT-4 结合机器人的突破性研究,通过 GPT-4 等 LLM 来生成 autopilot 上的一系列模拟机器人任务,使机器人的零样本学习和真实世界适应成为了现实。

方法介绍
如下图 2 所示,GenSim 框架通过程序合成生成模拟环境、任务和演示。GenSim pipeline 从任务创建器开始,prompt 链以两种模式运行,即目标导向模式和探索模式,具体取决于目标任务。GenSim 中的任务库是一个内存组件,用于存储之前生成的高质量任务,任务库中存储的任务可用于多任务策略训练或微调 LLM。
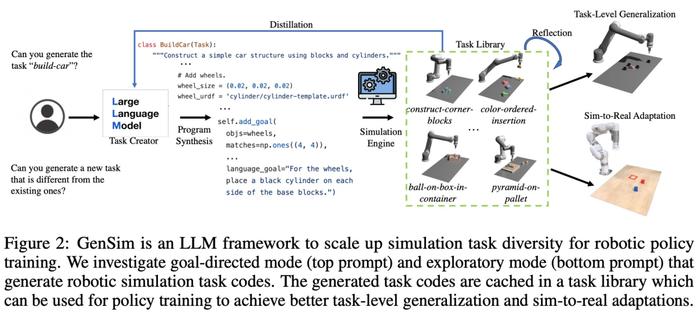
任务创建器
如下图 3 所示,语言链会首先生成任务描述,然后再生成相关的实现。任务描述包括任务名称、资源和任务摘要。该研究在 pipeline 中采用少样本 prompt 来生成代码。
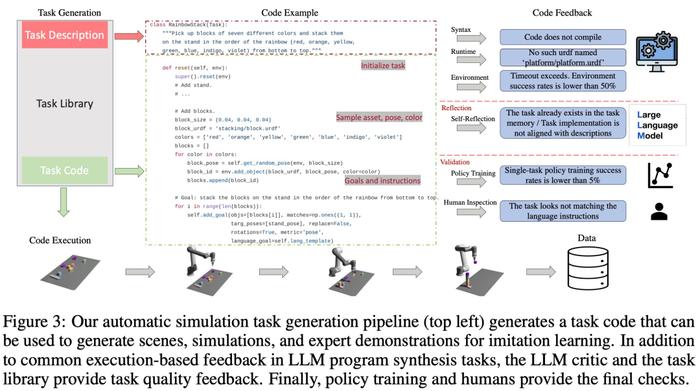
任务库
GenSim 框架中的任务库会存储任务创建器生成的任务,以生成更好的新任务和训练多任务策略。任务库是根据人工创建的基准中的任务进行初始化的。
任务库为任务创建器为描述生成阶段提供了作为条件的先前的任务描述,为代码生成阶段提供了先前的代码,并 prompt 任务创建器从任务库中选择参考任务作为编写新任务的样例。完成任务实现并通过所有测试后,LLM 会被 prompt,以「反思(reflect)」新任务和任务库,并形成是否应将新生成的任务添加到库中的综合决策。
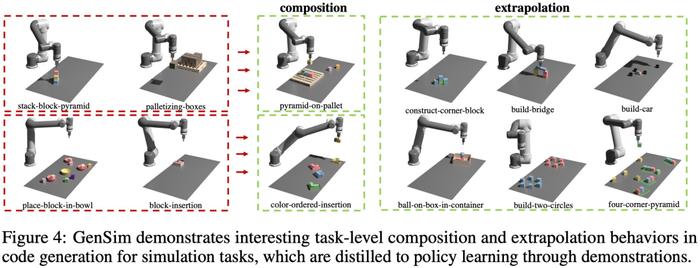
如下图 4 所示,该研究还观察到 GenSim 表现出有趣的任务级组合和外推行为:
LLM 监督的多任务策略
生成任务后,该研究使用这些任务实现来生成演示数据并训练操作策略,并使用与 Shridhar et al. (2022) 类似的双流传输网络架构。
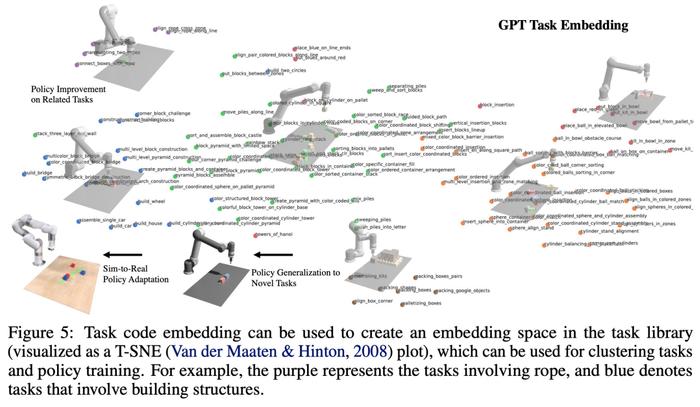
如下图 5 所示,该研究将程序视为任务和相关演示数据的有效表征(图 5),就可以定义任务之间的嵌入空间,其距离指标对于来自感知的各种因素(例如对象姿态和形状)更加稳健。
实验及结果
该研究通过实验来验证 GenSim 框架,针对以下具体问题:(1)LLM 设计和实现模拟任务的效果如何?GenSim 可以改进 LLM 在任务生成方面的表现吗?(2) 对 LLM 生成的任务进行训练是否可以提高策略泛化能力?如果给出更多的生成任务,策略训练是否会受益更多?(3) 针对 LLM 生成的模拟任务进行预训练是否有利于现实世界的机器人策略部署?
评估 LLM 机器人模拟任务的泛化能力
如下图 6 所示,对于探索模式和目标导向模式任务生成,少样本和任务库的两阶段 prompt 链可以有效提高代码生成的成功率。
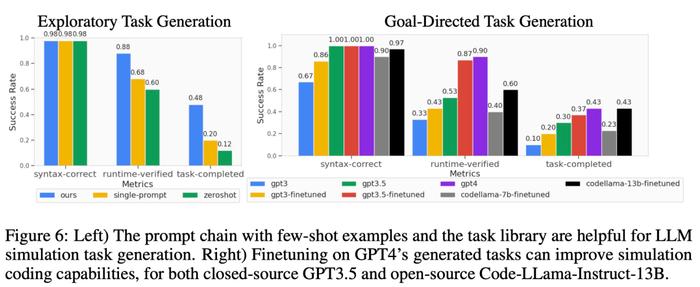
任务级泛化
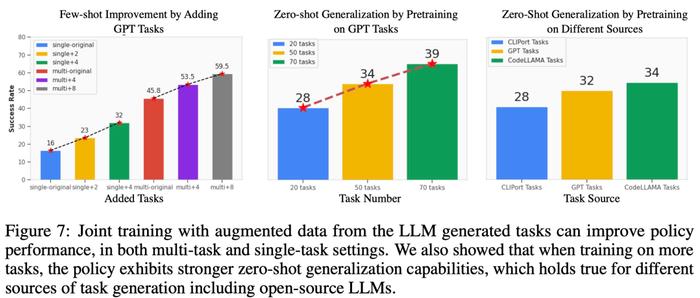
对相关任务的少样本策略优化。从下图 7 左可以观察到,联合训练 LLM 生成的任务可以将原始 CLIPort 任务上的策略性能提升 50% 以上,尤其是在低数据情况(如 5 个 demo)下。
对未见过任务的零样本策略泛化。从图 7 中可以看到,通过对 LLM 生成的更多任务进行预训练,研究者的模型可以更好地泛化到原始 Ravens 基准中的任务。图 7 右中,研究者还对人工编写任务、闭源 LLM 和开源微调 LLM 等不同任务源上的 5 个任务进行了预训练,并观察到了类似的零样本任务级泛化。
使预训练模型适应真实世界
研究者将模拟环境中训练的策略迁移到了真实环境中。结果如下表 1 所示,在 70 个 GPT-4 生成的任务上进行预训练的模型在 9 个任务上进行了 10 次实验,取得 68.8% 的平均成功率,与仅在 CLIPort 任务上进行预训练的基线模型相比提升了 25% 以上,与仅在 50 个任务上预训练的模型相比提升了 15%。
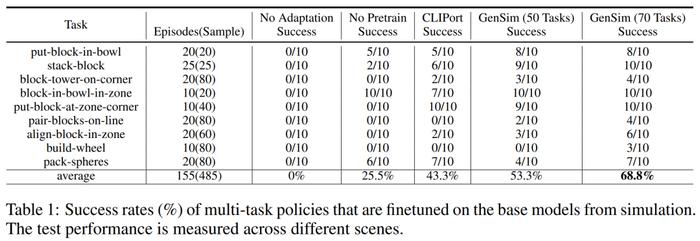
研究者还观察到,对不同模拟任务的预训练提高了长期复杂任务的稳健性。比如说,GPT-4 预训练的模型在真实世界的 build-wheel 任务上表现出了更加稳健的性能。

消融实验
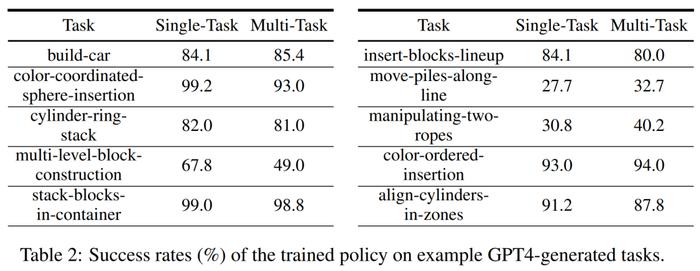
模拟训练成功率。在下表 2 中,研究者在拥有 200 个 demo 的生成任务子集上,演示了单任务和多任务策略训练的成功率。对于 GPT-4 生成任务的策略训练,它的平均任务成功率为单任务 75.8%,多任务 74.1%。
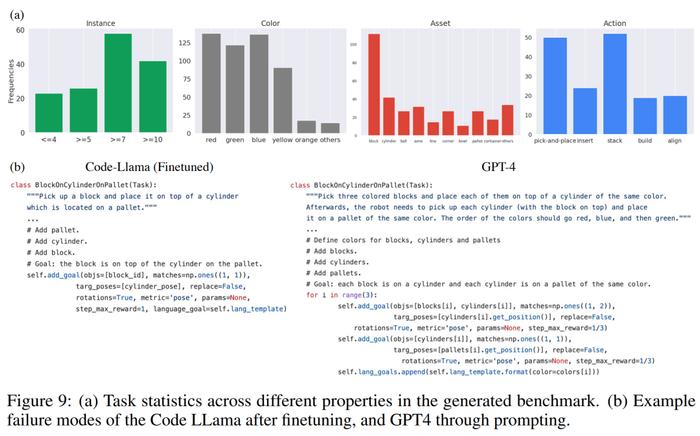
生成任务统计。下图 9 (a) 中,研究者展示了 LLM 生成的 120 个任务的不同特征的任务统计。其中 LLM 模型生成的颜色、资产、动作和实例数量之间存在着有趣的平衡。例如,生成的代码包含了很多超过 7 个对象实例的场景,以及很多拾起 - 放置原始动作和块等资产。
代码生成比较。下图 9 (b) 中,研究者定性地评估了 GPT-4 和 Code Llama 的自上而下实验中的失败案例。
更多技术细节请参阅原论文。
