


本文提出了一种简单有效的方法来实现不同扩散模型之间的合作。
近一两年,扩散模型 (diffusion models) 展现出了强大的生成能力。不同种类的扩散模型性能各异 —— text-to-image 模型可以根据文字生成图片,mask-to-image 模型可以从分割图生成图片,除此之外还有更多种类的扩散模型,例如生成视频、3D、motion 等等。
假如有一种方法让这些 pre-trained 的扩散模型合作起来,发挥各自的专长,那么我们就可以得到一个多功能的生成框架。比如当 text-to-image 模型与 mask-to-image 模型合作时,我们就可以同时接受 text 和 mask 输入,生成与 text 和 mask 一致的图片了。
CVPR 2023 的 Collaborative Diffusion 提供了一种简单有效的方法来实现不同扩散模型之间的合作。

论文: https://arxiv.org/abs/2304.10530
代码: https://github.com/ziqihuangg/Collaborative-Diffusion
网页: https://ziqihuangg.github.io/projects/collaborative-diffusion.html
视频: https://www.youtube.com/watch?v=inLK4c8sNhc
我们先看看不同扩散模型合作生成图片的效果:

当 text-to-image 和 mask-to-image 通过 Collaborative Diffusion 合作时,生成的图片可以达到和输入的 text 以及 mask 高度一致。

给定不同的多模态输入组合,Collaborative Diffusion 可以生成高质量的图片,而且图片与多模态控制条件高度一致。即便多模态输入是相对少见的组合,例如留长头发的男生,和留寸头的女生,Collaborative Diffusion 依旧可以胜任。
那不同的扩散模型究竟怎样实现合作呢?
首先,我们知道,扩散模型在生成图片的过程中,会从高斯噪声开始,逐步去噪,最终得到自然图像。

图片来源:CVPR 2022 Tutorial: Denoising Diffusion-based Generative Modeling: Foundations and Applications
基于扩散模型迭代去噪的性质,我们的 Collaborative Diffusion 在去噪的每一步都会动态地预测不同的扩散模型如何有效合作,各取所长。Collaborative Diffusion 的基本框架如下图所示。
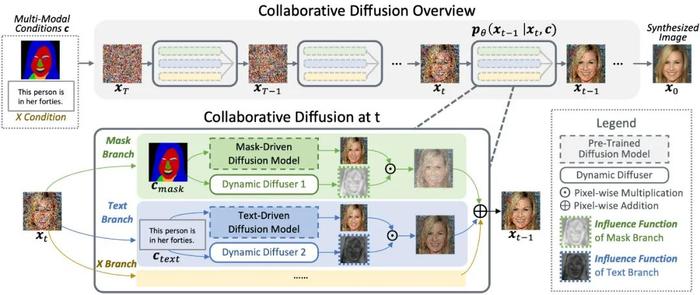
我们在每一步去噪时,用 Dynamic Diffusers 动态地预测每个扩散模型对整体预测结果带来的影响(也就是 Influence Functions)。Influence Functions 会选择性地增强或者减少某个扩散模型的贡献,从而让各位合作者(也就是扩散模型)发挥专长,实现合作共赢。
值得注意的是,预测得到的 Influence Functions 在时间和空间上都是适应性变化的。下图展示了 mask-to-image 和 text-to-image 模型合作时,在不同时间和空间位置的 Influence Functions 强度。

从上图中我们可以观察到,在时间上,决定 mask-to-image 模型影响的 Influence Functions 在去噪初期很强(第一行左边),到后期逐渐变弱(第一行右边),这是因为扩散模型在去噪初期会首先形成图片内容的布局,到后期才会逐渐生成纹路和细节;而在多模态控制人脸生成时,图片的布局信息主要是由 mask 提供的,因此 mask 分支的 Influence Functions 会随着时间由强变弱。与之相对应地 text-to-image 模型的 Influence Functions(第二行)会随着时间由弱到强,因为 text 提供的多数信息是与细节纹路相关的,例如胡子的浓密程度,头发颜色,以及与年龄相关的皮肤皱纹,而扩散模型的去噪过程也是在后期才会逐步确定图片的纹理以及细节。
与此同时,在空间上,mask-to-image 模型的 Influence 在面部区域分界处更强,例如面部轮廓和头发的外边缘,因为这些地方对整体面部布局是至关重要的。text-to-image 模型的 Influence 则在面中,尤其是脸颊和胡子所在的区域较强,因为这些区域的纹理需要 text 提供的年龄,胡子等信息来填充。
Collaborative Diffusion 的通用性
Collaborative Diffusion 是一个通用框架,它不仅适用于图片生成,还可以让 text-based editing 和 mask-based editing 方法合作起来。我们利用在生成任务上训练的 Dynamic Diffusers 来预测 Influence Functions,并将其直接用到 editing 中。如下图所示:




完整的实验细节和实验结果,以及更多图片结果,请参考论文。
总结
(1) 我们提出了 Collaborative Diffusion,一种简单有效的方法来实现不同扩散模型之间的合作。
(2) 我们充分利用扩散模型的迭代去噪性质,设计了 Dynamic Diffuser 来预测在时间和空间上均有适应性的 Influence Functions 来控制不同的扩散模型如何合作。
(3) 我们实现了高质量的多模态控制的人脸生成和编辑。
(4) Collaborative Diffusion 是一个通用的框架,不仅适用于图片生成,还适用于图片编辑,以及未来更多的基于扩散模型的其他任务。
