

(头图中 50% 的代码由 AI 编写)
来源:嫑关注
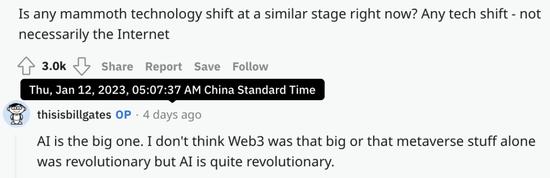
最近,比尔盖茨在 reddit 回答网友提问。有人问当下‘巨大的技术变革’是什么时,他回答说:
‘AI 是个大人物。我不认为 Web3 有那么大,或者元宇宙本身的东西是革命性的,但 AI 是相当革命性的。’(Google 翻译)
‘AI 是重要的。我不认为 Web3 那么重要或者说单独的元界是革命性的,但 AI 是相当革命性的。’(ChatGPT 翻译)
能和盖茨在 Web3 和人工智能的判断上一致,让我很开心。
另一件事,发生在朋友圈里。网易副总裁、杭州研究院执行院长汪源在讨论微软加大投资 OpenAI 能否赚钱时,说到:

这句话透露了两个信息:1. 网易杭研在大面积尝试应用 OpenAI 的能力;2. 为此要付不少服务费,但也愿意。
在网易工作过的都知道,要做一件对外付很多钱的事情,那一定是下了很大决心的

可是,就在两个月前,OpenAI 还没有发布 ChatGPT 的日子,业界对 AI 其实是悲观的。
L4 级自动驾驶被证明太难做到了,很多公司开始放弃。我有一个在头部公司做核心算法的朋友,已经选择转行了。
AI 四小龙也风头不再,探索出的业务模式变成外包项目为主,且技术含量越来越低。
为什么 ChatGPT 一推出,会带来 180° 的态度变化?
这两个月,我和 ChatGPT 对话数百条,参加了三场相关的研讨会,与十几位学术界、企业界的专家交流,当然也读了很多资料,对以下问题形成了一些观察和思考。
ChatGPT 与以往的 AI 不同在哪里?它为什么有可能成为通用人工智能?
通用人工智能对信息技术行业最直接的冲击是什么?
商业机会在哪里?
行业格局会怎样?
个人职业发展会受到什么影响?
下面就谈一下我的观点,期待你的批评指正。
一、‘大模型’敲开了通用人工智能的大门
ChatGPT 用的方法叫‘大型语言模型(Large Language Models)’,简称 LLMs。中文习惯称为‘大模型’。
简单说,它的思路就是把尽可能大量大量大量大量的数据通过 Transformer 架构做机器学习,就能从数据中学到很多很多很多很多能力,多到超出原始设计者的想象。
比方说,它在翻译方面的能力,不输于,甚至超过了专业的机器翻译系统。
本文开头机翻的比尔盖茨的话,我觉得 ChatGPT 就比 Google 翻译得要好上一个层次。唯一瑕疵是用了比较生僻‘元界’,而不是更常用的‘元宇宙’。但当我告诉它‘元宇宙’更常用后,它立刻就能修正翻译:
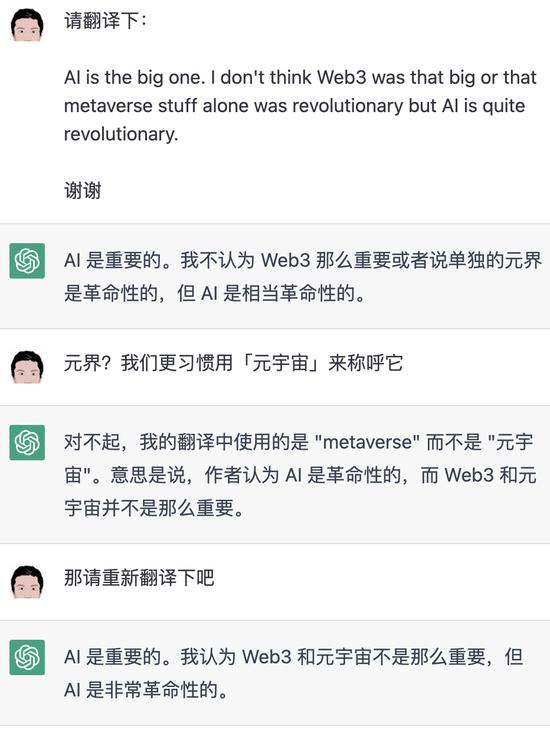
据说,翻译能力并不是 ChatGPT 特别着意打造的,它只是读的多语言数据多了,就会了

再比如,ChatGPT 偶然把源代码加到了训练数据里,结果发现 AI 的推理能力获得了巨大提升。
传闻说,ChatGPT 在发布时,只是被当成又一个新版本的 demo 而已,OpenAI 并没觉得它会多强大(前几个版本市场反应也是寥寥)。是网友贴在社交媒体的对话截图,让 OpenAI 才知道,原来它还能这样这样这样这样这样!
有没有一丝丝觉得,ChatGPT 的机器学习能力,已经很像人类的学习过程了?
让小孩子学编程的主要原因,是锻炼孩子的逻辑思维能力。这不和 AI 读代码学推理是一回事吗?
古人就说,‘读书百遍其义自见’,‘熟读唐诗三百首,不会作诗也会吟’。如果有一个少年,他可以不眠不休地快速读书。我们不知道他读完全世界所有书之后会是什么样,但相信他一定会很厉害。
如此接近人,让很多专家承认,我们终于敲开了通用人工智能(Artificial General Intelligence,下文简称 AGI)的大门了!
以前的 AI,不是 AGI,是因为它们的模型只能做一件事。人脸识别的就是识别人脸,缺陷检测的就是检测缺陷(且只能检测一种缺陷,换了缺陷就得换模型)。AlphaGo 只会下围棋,换成五子棋就会被我狂虐。
而 ChatGPT 已经能够触类旁通,把从 A 学到的能力,用在 B、C、D、E、F 上。
学术界用‘涌现(Emergent)’这个词来表述这种情况。请记住这个词,后面还会用到。
延续 ChatGPT 的一个研究热点是多模态大模型。简单理解,就是把语音、图像、视频等等各种类型的数据都灌进去,看能否用一个模型解决所有媒体的 AI 生成问题。
如果成功,那么再大胆假设一下,凡是数据,是不是都可以交给这个模型训练,让它学会如何从 A 生成 B?比如,从剧本直接生成电影,从 PRD 直接生成可执行的 App,从口头描述直接生成 3D 人物,从需求直接生成一切!
顺着这个逻辑,距离 AGI 是不是不远了?可别那么乐观。
现在只是打开了门。既不知道门后有什么,也不知道是不是开对了门。还有太多太多未知要面对和解决。
但这并不妨碍我们思考下,AGI 的世界,会对产业和我们个人带来什么变化。
有的变化,可能已经开始了……
二、AGI 的革命性不仅体现在智能本身
假定 AGI 已经实现。那么用 AI 可以代替人力,提升生产效率,降低生产成本,在更多领域释放 AI 的力量。其革命性毋庸置疑。
我想从另一个角度来探讨其革命性,那就是对信息技术自身的影响。用这样的终局思维,可以倒推出当下要做什么。
我认为,革命性的技术应该满足至少一个标志:
它让几乎每个软件系统都要做改造,甚至重做
符合这个标准的技术,之前有:
图形界面。成为软件系统的标配
Web 2.0。导致大量传统应用系统向 Web 迁移
移动互联网。导致几乎任何应用都要开发移动版。
Web3 不符合这个标准。我另有一文看衰它。
元宇宙当下和近期也不符合。AGI 实现之后,太多人无所事事,倒是有可能在元宇宙里醉生梦死。我会在本文最后一部分做分析。
我认为 AGI 是符合的。它能让所有软件系统几乎都要改造甚至重做,哪怕其核心功能并不需要智能。这是因为它重新定义了‘接口(Interface)’。
无论用户界面(UI),还是软件系统之间的接口(API),它都会重新定义。
现在我们想要一个结果,需要去了解计算机的能力,掌握各种软件的操作方法,还要把自己的意图正确拆解为若干个操作软件的步骤,执行之,才能得到。
AGI 之后,人类终于可以用‘说话’这种方式和计算机交互。说话不方便时就打字。打字费劲?脑机接口可以期待下。
‘说’出想要的结果,就能得到结果。可能不尽如人意,再‘说’出修改意见,效果即时呈现。当 UI 已可以如此美好,碰鼠标、摸屏幕的频率都会降低。
用户操作习惯的迁移,会逼所有软件,都得提供‘自然语言界面(Natural Language Interface,简称 NLI)’。这是我生造的词,指的是以自然语言为输入的接口。
不仅用户界面要 NLI,API 也要 NLI 化。这是因为用户发出的宏观指令,往往不会是一个独立软件能解决的,它需要很多软件、设备的配合。
一种实现思路是,入口 AI(比如 Siri、小爱同学,机器人管家)非常强大,能充分了解所有软件和设备的能力,且能准确地把用户任务拆解和分发下去。这对入口 AI 的要求非常高。
另一种实现思路是,入口 AI 收到自然语言指令,把指令通过 NLI 广播出去(也可以基于某些规则做有选择的广播,保护用户隐私),由各个软件自主决策接不接这个指令,接了要怎么做,该和谁配合。
第二种思路,我认为更有可能成为行业标准。单 AI 搞定一切不太符合目前的技术路线和商业环境。各个软件在各自的专业领域里,能做出更佳的 AI 决策。第四部分会详述。
举个例子,我对 Siri 说:‘我得新冠了’。Siri 把这句话广播给手机上的所有 App。于是,大家开始各自干活:
Apple Watch 打开了 24 小时血氧监测模式
米家 App 让空调提高温度,并询问我是否马上躺下休息,它可以关闭灯光和窗帘
饿了么建议我吃清淡食物,并推荐几款粥做明天的早餐,让我选择、预订
叮当买药推荐了附近能最快速度送到的退烧药,问我是否下单
猫眼电影建议我取消后天的电影票
Keep 通知我已取消未来一个月内预约的所有操课,还暂停了所有打卡
钉钉帮我起草了病假申请
微信问我要不要发个朋友圈?
当 NLI 成为事实标准,那么互联网上软件、服务的互通性会大幅提升,不再受各种协议、接口的限制。
比如现在华为、阿里、腾讯等都在争抢的物联网操作系统,表面看好像是在做内核,其实本质上是想成为最重要的那个万物互联的协议。
万物想要互联,大家首先要遵守同一个协议。谁的协议成为主流,谁就拥有了最高的话语权。
兼容多种协议,对厂商来说要增加很多成本。如果不兼容,就变成了所支持协议的附属。如果有个通用协议,就好了。
自然语言就是最好的通用协议,谁都可以兼容,谁都无法控制。甚至,说汉语、英语、爪哇语等任何语言都行。
在实现层面,NLI 的接口能极致简单。看看 ChatGPT 的 API 就知道了。
强大如 ChatGPT,无所不知,无所不晓,却只有一个接口函数(https://beta.openai.com/docs/api-reference/completions),16 个参数。
16 个参数里,最重要的只两个:model 和 prompt。其余的都是对生成结果的细节做控制,比较低频。
Model 是选择调用哪个模型。不同模型能力有所不同,价格也不同。
Prompt 是最核心的参数。它就是你在 ChatGPT 聊天框里输入的内容。完全自然语言,想怎么写都行。
所以,NLI 可以极简到甚至只有一个 prompt 参数,就能让所有软件系统形成协作。所有复杂的细节,都被处理 prompt 的 AI 解决了。
人与人,人与机器,机器与机器,都实现了无限制的交流。
为了支持 NLI,所有软件系统都必须集成一个 AI,以 AI 为总控来处理输入,生成输出。这就是 AGI 对信息技术领域带来的革命性变化。
其实相关的研究早就已经开展。在面向对象(Object-Oriented)之后,就有人提出面向智能体(Agent-Oriented)的概念,认为多智能体自治是未来构造软件的主要架构。可惜,当时没有人知道‘智能’在哪里。20 多年后,这项研究可以落地了。
三、AGI 革命带来的商业机会
敲开 AGI 的大门,会看到很多很多弯弯曲曲的道路,都有可能通向 NLI,也可能不通。不管结果如何,现在路边就有可以尝试挖掘的金矿。
ChatGPT 及 DALL-E 等从文字生成图像的产品,被统称为 AIGC(AI Generated Content)类的产品。
它们的基础能力是根据一串输入(prompt),生成各种内容并输出。本质上来说,所有的软件系统,都是根据输入,生成输出。所以理论上来说,只要 AI 的能力足够强,是可以完成目前计算机能处理的所有任务的。只不过要从效果和成本两个维度看用 AI 还是传统方法更合适。
评价效果的分水岭,是我们把 AI 的输出当建议,还是当决策。
我们让 ChatGPT 写文章,但不会让它直接把文章发出去,而是一定要看过、改过再发。这就是把 AI 的输出当建议。
自动驾驶,该加速还是减速,该怎么转向,都是 AI 做出决定,并立即执行。这就是决策。
现在的 AI 经常‘一本正经地胡说八道’,让它决策非常不靠谱。所以目前的 AI 产品,应该在‘建议’这个场景下做设计,把修正和决策的空间留给人类。
对话是典型的建议场景,因为对话结论的执行还是需要人。ChatGPT 呈现的也就是一个 Chatbot,很容易自然想到在各种对话场景来使用它。比如客服、智能音箱、AI 老师等。
我认为能成功的 AI 对话场景要满足如下条件:
用户需要知道是在与 AI 对话。否则,就是诈骗了
对话频次要足够高。没人愿意为使用 AI 付高价,所以它不可能是低频高客单价,只可能走高频低客单价。比如 ChatGPT 目前虽然 C 端访问量巨大,但多数人都是猎奇,频次不会高。刚需高频访问的,只有研究它的人。这类人虽然支付能力强,但人数非常少。所以我认为 ChatGPT 即将推出的每月 $42 的 premium 版太贵,就是用来收割研究者的,不会获得商业成功。
现在的 ChatGPT 每次对话成本大约 1 美分。如果按每人每天会使用 5 次搜索引擎看,ChatGPT 想替代搜索引擎,每月成本就是 1.5 美元。但对我来说,抛开研究因素,1.5 美元的月租我都不会付。因为它输出的结果,远没到让我愿意抛弃免费的搜索引擎
我们和人对话,不外乎希望获得有价值的信息,或者有温度的抚慰。按照这三个条件看,有价值的信息是能符合的。
客服毫无疑问是成功的场景。事实上客服界早已经被 AI 统治了。大模型给对话能力带来恐怖的提升,且降低了限定领域内的预训练难度。虽然当前成本可能比传统 AI 有所增加,但这是肯定会下降的。综合来看,客服全面迁移到大模型是很可以期待的。
AI 老师也值得期待,毕竟真人老师 1v1 的成本太高了。虽然有胡说八道之嫌,但足够的领域数据做训练,再加上测验和真人补差,效果可能比全真人老师更好。
我的朋友高老师,是个教人工智能的名师。他在自己的学生群里,就接了个 ChatGPT 回答学生的 Python 问题,完全省下了助教的费用。
前面说过,ChatGPT 是用大量代码做过训练的,所以解答编程问题的靠谱度还是可以的。其它学科领域只要做了足够训练,相信也能不错。
而有温度的抚慰,多数情况下,AI 提供不了。
比如,AI 心理咨询我认为不会成功。因为咨询的核心需求是得到共情、认可和偶尔的棒喝。从 AI 获得这三样,就算话是对的,感受也是错的。‘只有 AI 接纳我’‘我 tm 还不如一个 AI 想得通透’,只会增加咨询者的心理负担。
单纯的闲聊,AI 不具备成本优势(找朋友闲聊是免费的,还能增进感情),也没有温度。它再会聊,也不会形成高频。
但不具备和真人聊天条件的场景,是有可能成功的。
比如和逝去的人对话,模仿 ta 的声音和说话习惯。在一些关键时间节点,能卖出高价格。但我觉得,让活着的人尽快和逝去的人完成分割,才是最大的善。
有人想做模拟名人的 AI。这个不会成功。我们都知道巴菲特午餐卖的并不是午餐,其实也不是和巴菲特说的那些话,而是我做过这件事本身。和 AI 巴菲特聊天,完全不可能达到同样效果。和刘德华、林志玲、鹿晗聊天同理。
不过也有特例。和名人 AI 聊真人不可能聊的话题,有可能成。比如和志玲姐姐聊不可描述之事……当然,这肯定是违法的了。
除了对话,另一类应用大模型的场景是辅助创作。
写文章、画画、编代码,都已经有成功例子。从中可以看出,AI 一定要集成到人工创作的场景里,才最好用。在这样的场景,才能行云流水地给 AI 提需求,和修正、发布 AI 给出的建议。比如我,已经决定对集成到 VS Code 里的 copilot 付费了,但用 ChatGPT 辅助写代码就太绕了。
按照这个模式推论,所有创作场景,都值得尝试下 AI 辅助。比如低代码开发,运营活动页搭建,短视频剪辑,BI 图表制作等有经验的人已经干腻了,没经验的人又干不好的场景。
AI 肯定比没经验的人干得好,且因为替有经验的人完成了大量乏味工作,而获得认可。
在没有获得‘决策’能力之前,大模型不太容易扩充新的应用场景。只能不断深入。
个人大模型,可能是个值得深入的方向。让通用大模型具备个性化能力,就能做带有个人风格的对话和创作。也许不能解决当下的痛点,但当做期货卖个未来,还是有可能吸引一些猎奇人士付费的。
四、对‘大模型’行业格局的预测
每次技术突破,都可能带来行业洗牌,形成格局巨变。但大模型,可能不会。
这要以大模型成功的四个核心要素来分析。这四个要素是:
算法
数据
工程技巧
大量的钱买来的算力和人工反馈
这四者缺一不可。算法是成功的首要条件,然后要喂给算法海量的数据(数据量级跃升,能带来更多能力的涌现),在买来的强大算力上运算,才能获得最基础的大模型。之后,要做 RLHF(Reinforcement Learning from Human Feedback),也就是买大量的人工工时,对 AI 生成的内容做人工标注反馈,使 AI 获知怎么做是更让人类满意的。然后就是用工程技巧做各种优化,其中包括大量的规则优化,就是把确定规则硬编码到模型中,以达到更好的效果,还能提升性能降低算力成本。
四个要素里,最‘不值钱’的是算法。因为早已都公开发表,所有人都知道。
ChatGPT 所用的 Transform 算法架构,来自 Google 发表的论文。
那为啥 Google 没率先推出惊艳大模型呢?官方说法是大公司担心伦理问题,怕输出的不靠谱回答给公司带来声誉损失,所以没有对外发布自己的产品。
我认为这完全是借口。面对这种突破性引领性的革命,任何公司都不可能忍住不去展示的。只要标明 beta,做好免责协议,就足够规避风险了。
数据也不构成太大的门槛。ChatGPT 训练用的数据都是网上公开的文本、代码等,只要花时间花精力爬取、整理,就都能获得。互联网巨头手上这么多年攒的数据,只会比 OpenAI 多,且有大量非公开的数据(但可能受法律限制,不能用来训练大模型)
Google、Meta、百度、腾讯、阿里等都具备做出匹敌甚至超过 ChatGPT 的实力,但没产品发布的唯一原因,只可能是他们低估了大模型的能力,没有做足够的投入。而 OpenAI 孤注一掷,砸大钱买算力和人工反馈,而且赌赢了。
相信巨头们,现在肯定不会闲着,都会堆资源来训练自己的大模型了。
在资源投入差不多的情况下,最后拼的就是工程技巧了。这里才是有商业秘密的地方。而且是挖来对方公司的人,也带不走的秘密。因为都是平时日日踩坑填坑,沉淀在代码里的各种优化,没有文档,没有分享。每个都细小不起眼,但累积起来的作用惊人。
比如都说抖音的推荐算法好。其实快手的算法和抖音大同小异。最大的差异,都在工程技巧上,抖音积累得更久更多,效果就更好。快手工程师只馋这个。
起步最早的 OpenAI 在工程技巧上已经具备了相当的优势,所以微软没有选择自己再搞个大模型,而是加大对 OpenAI 的投资力度。
除了掰着指头数得过来的这几家巨头,剩下的都拼不起匹配的资源。因此,大模型的核心玩家,还是互联网巨头们,这个格局不会变。
但蛋糕不是只有他们能吃到。
巨头训练出的大模型,是通用大模型。如果把 AI 比喻成人,那么这些大模型相当于读完了中小学的人。达到了通识的高峰,上晓天文下知地理,但只会纸上谈兵,解决不了真正的问题。必须要再经过大学的专业训练,才能在某一个专业方向成为有价值的人。
教大模型上大学,训练出垂直大模型,这是中小公司的机会,巨头做不了。
因为在垂直领域训练 AI,需要垂直领域的数据。这些数据都掌握在各个领域的公司手里,巨头拿不到。
但这些公司并不能摆脱巨头的大模型,反而是很依赖。因为你不可能让一个婴儿直接上大学。
巨头做 AI 的 K12 学校训练通用大模型,其它公司做 AI 的大学训练垂直大模型,这就是行业格局架构。
垂直领域的公司有很多,谁能先动手、快动手,谁历史数据储备得足,谁就能在垂直方向上获得先机,甚至在领域内重新洗牌。比如所有文档都云化了的各种云文档,就比 Word 更有做好个人大模型、公司大模型的机会,借机把 Office 拉下神坛。
创业公司有机会吗?没有垂直数据,没有对 AI 的输出做修正的功能,没用应用结果的生态基础,难度很大。
所以,大模型的技术特点决定了,它虽然具有革命性,但不能革行业格局的命。
数据如此重要,数据的盗取、买卖、非法使用肯定会出现。这倒可能是搅局者的机会所在。这对相关的立法和执法,提出了挑战。
五、有哪些个人职业机会
在 AlphaGo 战胜李世乭时,很多人恐慌被 AI 替代。彼时若干行业大佬预测,AI 只能代替重复性体力工作,创意型的脑力工作它代替不了。
刚刚 6 年过去,情况完全变了。AI 已经能写作、画画、编程了,且做得还不赖。
据说,在音乐创作领域,AI 早已经大行其道。很多神曲,都是 AI 的作品。对此我虽无渠道求证,但比较相信。
所谓创意,不过就是在各种组合中找到那个最优的。可能的组合有非常多,哪个最优,需要经年累月很多人去测试。测试成功了,就是名人,不成功的就是普通人。慢慢地,套路被总结出来,就变成机械重复了。
计算机完全有能力完成这个过程,且加速它。
那人还能干嘛呢?让 AI 更强啊。
远的不说,只说近的。现在就有一个新职业诞生:提示工程师(Prompt Engineer)。
这是干啥的?简单说,就是陪 AI 聊天的……
前面讲了大模型的涌现能力。它到底能涌现出什么,是需要在与人的对话中才能展现的。
提示工程师的工作目标,就是变着法子地和 AI 说话,来激发其潜能,把涌现出的能力固化下来。
另外,带 AI 上大学,需要为其准备数据。这数据并不是随便导入就行的,得静心整理、设计。
简单说,基于通用大模型训练垂直大模型,需要提供 prompt + completion 格式的训练数据。
按 OpenAI 文档的说法,有 200 条数据就能看到明显的效果。条数越多,效果越好。
按大模型理论,数据的质量比条数更重要。
而我们积累的数据,多数都只是 completion。需要提示工程师来构造高质量的 prompt,才能训练出好用的垂直大模型。
某种意义上说,提示工程师就是 AI 的大学教授啊!
这个岗位,至关重要。技术背景在此并不占优,可能产品经理、运营来做更合适,因为更懂业务。
还有一个有望获得新机会的岗位,是 UI/UE 设计师。
系统间的 NLI 还很远,但 UI 的 NLI 化,已箭在弦上。
还记得罗永浩的坚果 TNT 工作站吗?虽然那时是笑话,但现在已是机会。
键盘鼠标之外,又增加了自然语言控制。传统 UI 的操作范式肯定会发生改变。
我判断,UI 设计的要点会越来越强调反馈,而不是键鼠操作。可能要留一定的微调能力,但像向导、创建、删除、批处理等,都会变成直接响应自然语言。‘What you see is what you say’会成为核心设计语言。
软件工程师也要做出调整。所有的软件设计可能都要 Agent-Oriented,这意味着模块化是强制必须的,然后交给 AI 去做满足用户需求的模块组合。
模块内部要多 AI,得看需求和粒度。当 AI 对算力的要求降到某个阈值时,可能简单的模块功能,也可以考虑用 AI 实现了。
如果说 AGI 的出现,率先让程序员的数量减少了,我一点儿也不奇怪。毕竟《产研的宿命就是让自己越来越不重要,直到被裁掉》
六、聊点儿科幻的
可以肯定的,AI + 机器人越成熟,对人力的需要就越少。那人怎么办?
坦率说,就算人最终被机器奴役,我也挺高兴的。这不也是符合进化法则吗?我只希望,如果发生这一天,那么要让我能亲历。
不过,我没那么悲观。我觉得,人的劳动价值越来越低,情感价值就越来越大。
情感本来就是具有种族排他性的。同宗同族更容易形成彼此的认同。机器种族再智能,只要非我族类,那么就不可能在情感上代替人类。
虽然我还是认为人类应该断绝感性拥抱全面理性,但是这方面的进化速度可能会低于 AI 的崛起速度。
所以,AI 世界里,少数人类,在不断完善 AI,多数人类依靠情感活着,用情感创造价值。
少数人类的成就感来自于创造更厉害的 AI,AI 的成就感来自于让多数人可以四体不勤地追求纯颅内高潮。人类繁衍的动力,是培养可以让 AI 更厉害的下一代,使人类可以更四体不勤,更多想象,更多交流。
因为四体不勤,我们对能源的消耗减弱了。因为追求想象,所以我们更多生活在元宇宙里。
慢慢地,我们成为数字蛀虫,被 AI 供养。AI 很有成就感,很开心这么做。
只要仍然有少数人凌驾在 AI 之上,优化 AI。他们依赖成就感而活着,那么人类的生存就没有威胁。
直到某一天,有 AI 涌现出了一种能力,可以消灭创造它的人……
这不是个自洽的科幻,纯粹胡言,可以不信。(我也不大信)
但要相信的是,我们得做好迎接 AI 的准备了。
