


近日,上海市儿童医院眼科的乔彤教授团队和上海交通大学医学院附属新华医院的郑策副教授在BMC Ophthalmology(《BMC眼科》)期刊上发表了一篇题为“Automated Detection of Steps in Videos of Strabismus Surgery Using Deep Learning”的文章,该研究开发了一个深度学习模型,用于自动检测斜视手术视频中的主要手术步骤。研究者认为,斜视手术步骤的自动分类识别可以辅助提高斜视手术规范化培训的有效性,也有望作为评估住院医师培训情况的重要手段。
斜视是指各种原因导致眼外肌协调运动失常,双眼不能同时注视同一物体的现象,是导致儿童视觉发育障碍的常见眼病。据了解,全球儿童斜视患病率约0.8%到6.0%不等。斜视除了影响美观外,还会导致弱视、双眼单视功能不同程度的丧失和自信心下降、自尊焦虑等社会心理后遗症。儿童斜视的早期发现和及时治疗至关重要,可以在矫正眼位、恢复外观的基础上,促进视力发育和双眼视觉功能的建立。
据乔彤介绍,目前临床上斜视的诊断高度依赖眼科医师专业检查和检查设备,耗费大量人力、物力,效率低、覆盖面小,应用场景局限在临床,“在中国等许多国家,能够完成斜视筛查的眼科医生数量有限,且眼科住院医师大多无法得到足够的、标准化的斜视手术培训和教育。人工智能(AI)与医学融合的时代已经到来。AI在斜视诊疗领域的应用研究起步较晚,目前大致可分为2类:识别诊断型及手术规划型。”
在上述研究中,团队采集了上海市儿童医院眼科的5位手术者的479个手术视频,将手术录像分割成3345个主要手术步骤片段。基于ICO斜视评估标准将斜视手术分为8个步骤:剪开结膜、钩取眼外肌、暴露眼外肌、预制缝线、分离眼外肌、测量位置、附着眼外肌及缝合结膜。并随机形成训练集、验证集和内部测试集。
由于手术视频不仅包括单帧静态图像信息,也包括时间维度的因果信息,因此,研究团队采用了两个神经网络嵌合的思路,其中卷积神经网络用于提取单帧图片中的静态手术动作信息,Transformer模型用于提取时间维度上的因果信息。模型构架主要包括输入端、中间模型和输出端三部分。研究者将神经网络设计为一个卷积神经网络(CNN)、一个递归神经网络(RNN)再串联一个门控递归单元(GRU)层三大版块:首先运用一个2017年由google团队提出的预训练的神经网络——DenseNet,提取出特征信息,包括单帧图片上的信息如RGP通道信息、空间信息等,并将它们降维压缩拉伸成空间向量信息,接着用注意力机制模型融合时间维度上的信息,最终输出预测结果。
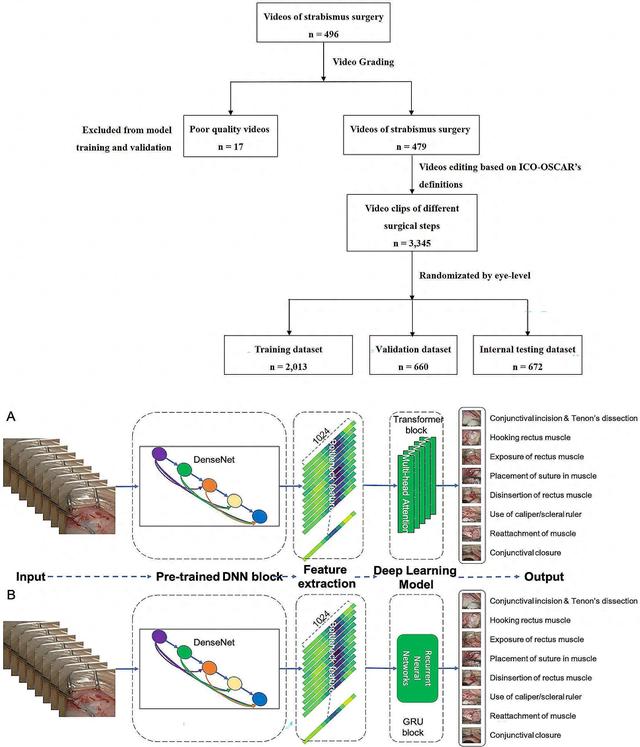
当前研究的流程图和模型构架示意图。图片来源:BMC Ophthalmology
研究结果表明,该深度学习模型在对不同手术步骤进行分类时表现出色(AUC = 1.00;准确率 = 96%)。说明基于手术视频的深度学习模型可以高精度地自动识别斜视手术步骤。
研究者认为,该项研究在许多临床环境中都具有潜力。住院医生学习斜视手术的学习曲线与基于反馈的教学指导密切相关,深度学习算法可通过实时提醒下一步操作,及对手术中的错误操作进行识别和警告,减少手术失误并指导手术操作,尤其是对新手。此外,未来还可基于此开发一种实时监督和客观手术评估的手术规范化培训系统,以提高斜视的整体手术疗效。
据悉,研究团队将进一步探究、验证深度学习模型在眼科手术规范化培训中的潜在应用价值。结合对比学习、计算机视觉等方法,拓展深度学习结果的可解释性和临床随访等多领域应用。
