

核心观点
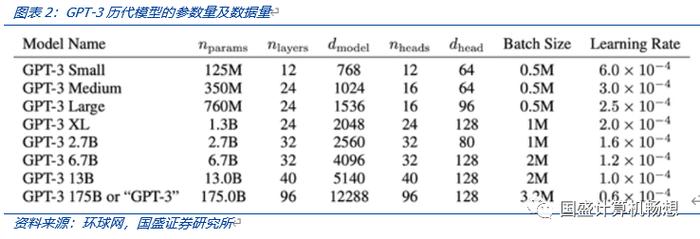
ChatGPT:大模型下计算量高速扩张,算力需求陡增。1)以前,人工智能大多是针对特定场景应用进行训练,难以迁移,属于小模型范畴;而ChatGPT背后的支撑为人工智能大模型,可大幅扩充适用场景、提升研发效率。OpenAI GPT3自发布以来,在翻译、问答、内容生成等领域均有不俗表现,也吸引了海内外科技巨头纷纷推出超大模型、并持续加大投入。2)在大模型的框架下,每一代GPT模型的参数量均高速扩张,GPT-3参数量已达到1750亿个。我们认为,ChatGPT的快速渗透、落地应用,也将大幅提振算力需求。
访问算力:初始投入近十亿美元,单日电费数万美元。1)根据Similarweb的数据,2023年1月,平均每天约有1300万独立访客使用ChatGPT。访问阶段算力每天发生,其成本成为衡量ChatGPT最主要投入的关键指标。2)我们以英伟达A100芯片、DGX A100服务器、现阶段每日2500万访问量等假设为基础,估算得出:在初始算力投入上,为满足ChatGPT当前千万级用户的咨询量,投入成本约为8亿美元,对应约4000台服务器;在单日运行电费上,参考美国平均0.08美元/kwh工业电价,每日电费约为5万美元,成本相对高昂。
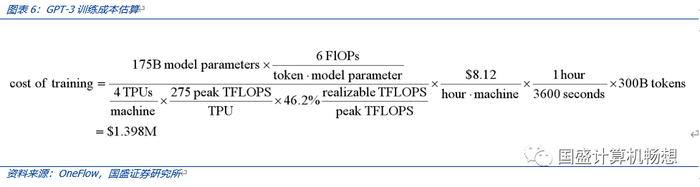
前期训练:公有云下,单次训练约为百万至千万美元。1)模型的前期训练成本也是讨论的重要议题。基于参数数量和token数量估算,GPT-3训练一次的成本约为140万美元;对于一些更大的LLM模型(如拥有2800亿参数的Gopher和拥有5400亿参数的PaLM),采用同样的计算公式,可得出,训练成本介于200万美元至1200万美元之间。2)我们认为,在公有云上,对于全球科技大企业而言,百万至千万美元级别的训练成本并不便宜,但尚在可接受范围内。
投资标的:1)服务器:浪潮信息、紫光股份、中科曙光等;2)芯片:景嘉微、寒武纪、海光信息等;3)IDC:宝信软件、万国数据、数据港、世纪华通等;4)光模块等。
风险提示:AI技术迭代不及预期风险、经济下行超预期风险、行业竞争加剧风险
报告正文
01
ChatGPT:大模型下计算量高速扩张,算力需求陡增
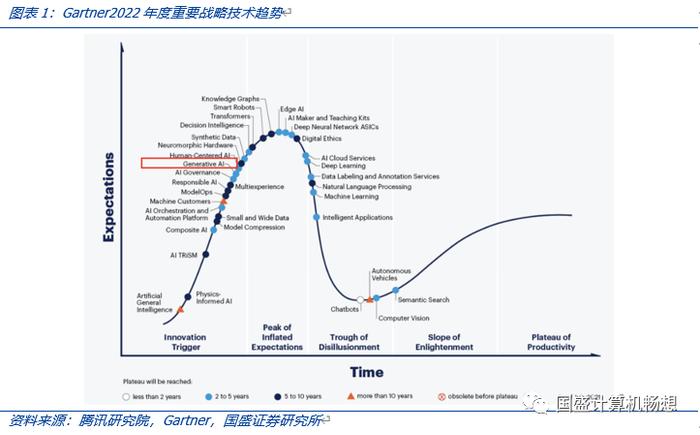
ChatGPT以大模型为基础,在翻译、问答、内容生成等领域表现不俗。1)ChatGPT是生成式AI的一种形式,Gartner将其作为《2022年度重要战略技术趋势》的第一位。2)根据腾讯研究院研究,当前的人工智能大多是针对特定的场景应用进行训练,生成的模型难以迁移到其他应用,属于“小模型”的范畴。整个过程不仅需要大量的手工调参,还需要给机器喂养海量的标注数据,这拉低了人工智能的研发效率,且成本较高。而ChatGPT背后的支撑是人工智能大模型。大模型通常是在无标注的大数据集上,采用自监督学习的方法进行训练。之后,在其他场景的应用中,开发者只需要对模型进行微调,或采用少量数据进行二次训练,就可以满足新应用场景的需要。这意味着,对大模型的改进可以让所有的下游小模型受益,大幅提升人工智能的适用场景和研发效率。3)因此大模型成为业界重点投入的方向,OpenAI、谷歌、脸书、微软,国内的百度、阿里、腾讯、华为和智源研究院等纷纷推出超大模型。特别是OpenAI GPT3大模型在翻译、问答、内容生成等领域的不俗表现,让业界看到了达成通用人工智能的希望。当前ChatGPT的版本为GPT3.5,是在GPT3之上的调优,能力进一步增强。
参数量、数据量高度扩张,算力需求陡增。在大模型的框架下,每一代GPT模型的参数量均高速扩张;同时,预训练的数据量需求亦快速提升。我们认为,ChatGPT的快速渗透、落地应用,也将大幅提振算力需求。
02
访问算力:初始投入近十亿美元,单日电费数万美元
Chatgpt月活过亿,访问量爆发式增长。根据Similarweb的数据,2023年1月,平均每天约有1300万独立访客使用ChatGPT,是2022年12月份的两倍多;累计用户超1亿,创下了互联网最快破亿应用的记录,超过了之前TikTok9个月破亿的速度。
访问阶段的算力每天发生,成为衡量ChatGPT投入的关键指标。
1)计算假设:
英伟达A100:根据OneFlow报道,目前,NVIDIA A100是AWS最具成本效益的GPU选择。
英伟达DGX A100服务器:单机搭载8片A100 GPU,AI算力性能约为5 PetaFLOP/s,单机最大功率约为6.5kw,售价约为19.9万美元/台。

标准机柜:19英寸、42U。单个DGX A100服务器尺寸约为6U,则标准机柜可放下约7个DGX A100服务器。则,单个标准机柜的成本为140万美元、56个A100GPU、算力性能为35 PetaFLOP/s、最大功率45.5kw。
2)芯片需求量:
每日咨询量:根据Similarweb数据,截至2023年1月底,chat.openai.com网站(即ChatGPT官网)在2023/1/27-2023/2/3这一周吸引的每日访客数量高达2500万。假设以目前的稳定状态,每日每用户提问约10个问题,则每日约有2.5亿次咨询量。
A100运行小时:假设每个问题平均30字,单个字在A100 GPU上约消耗350ms,则一天共需消耗729,167个A100 GPU运行小时。
A100需求量:对应每天需要729,167/24=30,382片英伟达A100 GPU同时计算,才可满足当前ChatGPT的访问量。
3)运行成本:
初始算力投入:以前述英伟达DGX A100为基础,需要30,382/8=3,798台服务器,对应3,798/7=542个机柜。则,为满足ChatGPT当前千万级用户的咨询量,初始算力投入成本约为542*140=7.59亿美元。
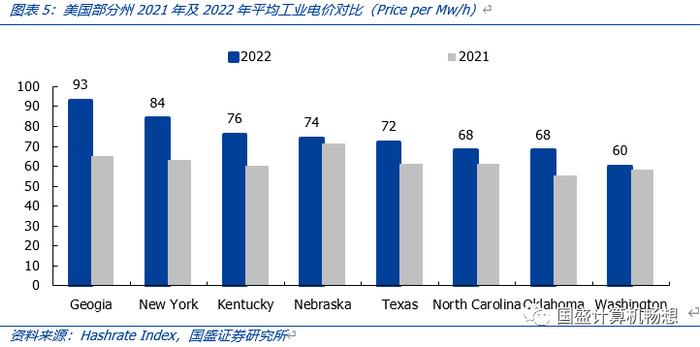
每月电费:用电量而言,542*45.5kw*24h=591,864kwh/日。参考Hashrate Index统计,我们假设美国平均工业电价约为0.08美元/kwh。则,每日电费约为591,864*0.08=4.7万美元/日。
03
前期训练:公有云下,单次训练约为百万至千万美元
模型的前期训练成本也是讨论的重要议题。根据估算,GPT-3训练成本约为140万美元;对于一些更大的LLM模型,训练成本约达到1120万美元。
1)基于参数数量和token数量,根据OneFlow估算,GPT-3训练一次的成本约为139.8万美元:
每个token的训练成本通常约为6N(而推理成本约为2N),其中N是LLM的参数数量;
假设在训练过程中,模型的FLOPS利用率为46.2%,与在TPU v4芯片上进行训练的PaLM模型(拥有5400亿参数)一致。
2)对于一些更大的LLM模型(如拥有2800亿参数的Gopher和拥有5400亿参数的PaLM),采用同样的计算公式,可得出,训练成本介于200万美元至1200万美元之间。
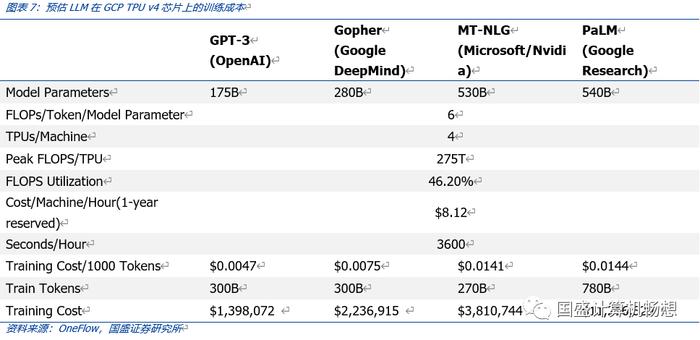
我们认为,在公有云上,对于以谷歌等全球科技大企业而言,百万至千万美元级别的训练成本并不便宜,但尚在可接受范围内、并非昂贵。
04
投资建议
1)服务器:浪潮信息、紫光股份、中科曙光等。
2)芯片:景嘉微、寒武纪、海光信息等。
3)IDC:宝信软件、万国数据、数据港、世纪华通等。
4)光模块等。
05
风险提示
AI技术迭代不及预期风险:若AI技术迭代不及预期,NLP技术理解人类意图水平未能取得突破,则对产业链相关公司会造成一定不利影响。
经济下行超预期风险:若宏观经济景气度下行,固定资产投资额放缓,影响企业再投资意愿,从而影响消费者消费意愿和产业链生产意愿,对整个行业将会造成不利影响,NLP技术应用落地将会受限。
行业竞争加剧风险:若相关企业加快技术迭代和应用布局,整体行业竞争程度加剧,将会对目前行业内企业的增长产生威胁。
具体分析详见2023年2月12日发布的报告《ChatGPT需要多少算力》
分析师 刘高畅 分析师执业编号S0680518090001
分析师 杨然 分析师执业编号S0680518050002
特别声明:《证券期货投资者适当性管理办法》于2017年7月1日起正式实施。通过微信形式制作的本资料仅面向国盛证券客户中的专业投资者。请勿对本资料进行任何形式的转发。若您非国盛证券客户中的专业投资者,为保证服务质量、控制投资风险,请取消关注,请勿订阅、接受或使用本资料中的任何信息。因本订阅号难以设置访问权限,若给您造成不便,烦请谅解!感谢您给予的理解和配合。
重要声明:本订阅号是国盛证券计算机团队设立的。本订阅号不是国盛计算机团队研究报告的发布平台。本订阅号所载的信息仅面向专业投资机构,仅供在新媒体背景下研究观点的及时交流。本订阅号所载的信息均摘编自国盛证券研究所已经发布的研究报告或者系对已发布报告的后续解读,若因对报告的摘编而产生歧义,应以报告发布当日的完整内容为准。本资料仅代表报告发布当日的判断,相关的分析意见及推测可在不发出通知的情形下做出更改,读者参考时还须及时跟踪后续最新的研究进展。
本资料不构成对具体证券在具体价位、具体时点、具体市场表现的判断或投资建议,不能够等同于指导具体投资的操作性意见,普通的个人投资者若使用本资料,有可能会因缺乏解读服务而对报告中的关键假设、评级、目标价等内容产生理解上的歧义,进而造成投资损失。因此个人投资者还须寻求专业投资顾问的指导。本资料仅供参考之用,接收人不应单纯依靠本资料的信息而取代自身的独立判断,应自主作出投资决策并自行承担投资风险。

